击败5000万美元向量数据库的Markdown文件

击败5000万美元向量数据库的Markdown文件
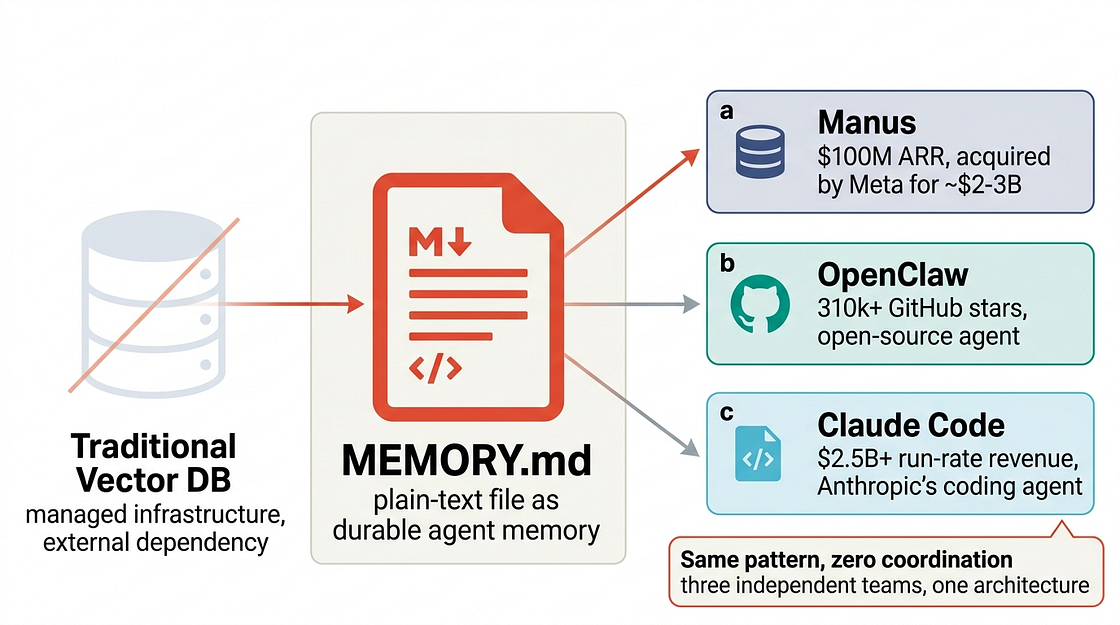
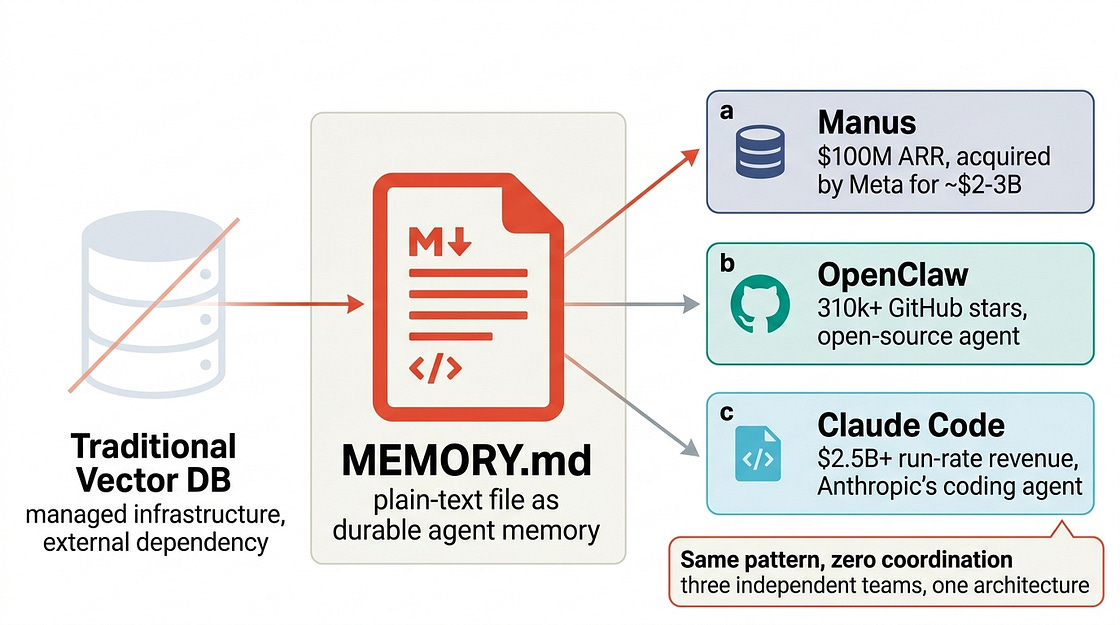
目前生产中最成功的三个AI代理平台以你存储购物清单的方式存储记忆。这听起来并不像听起来那么疯狂。
我花了过去两周拆解Manus、OpenClaw和Claude Code的架构。这些不是周末的爱好项目。Manus在 launch 后八个月达到1亿美元ARR,并被Meta以2-3亿美元的价格收购。Claude Code的运行率收入在2026年2月超过25亿美元。OpenClaw拥有超过310,000个GitHub星标。
它们三个都使用普通的Markdown文件作为主要记忆系统。不是托管向量数据库。不是5000万美元的基础设施产品。Markdown文件。
本文你将学到:
收敛模式:为什么三个独立的、生产规模的代理系统都选择了基于文件的记忆
上下文工程逻辑:Manus如何将”文件系统作为上下文”转变为节省实际资金的单位经济策略
混合架构:OpenClaw如何在Markdown之上分层语义检索,而不将权威交给外部数据库
平衡点:文件何时停止工作以及你实际需要数据库的时间(比你想象的要晚)
三个团队,一个奇怪的技巧
这就是有趣的地方。这三个项目没有互相复制。它们独立到达了相同的模式,为不同的用户解决不同的问题。
Manus是一个面向消费者的AI代理,处理复杂的多步骤任务。OpenClaw是一个开源的个人AI助手。Claude Code是Anthropic的官方编码代理。不同的团队。不同的代码库。不同的商业模式。
但打开它们的架构,你会发现相同的核心思想:文件系统是记忆层。模型读写普通文件(通常是Markdown),这些文件是代理知道什么和正在做什么的持久、可检查的记录。
Yaohua Chen在DEV Community上的一篇文章将此称为”趋同进化”,这个框架被保留下来。但更有用的问题不是”这不是很整洁吗?”而是”为什么这一直在发生?”
答案在于LLM的实际工作方式,以及大规模运行它们的经济学。
Manus:文件是商业策略的1亿美元证明
Manus是最有趣的案例,因为其团队实际上发表了他们选择文件而不是数据库的原因。在2025年7月的一篇工程帖子中,Manus联合创始人Yichao “Peak” Ji以不同寻常的坦率阐述了这一逻辑。
核心洞察:Manus处理每1个输出token平均100个输入token。这个比率使得输入成本成为主导变量。而Claude Sonnet上缓存和未缓存输入token之间的价格差异大约是10倍(约0.30美元对每百万token3美元)。
这个数字几乎解释了Manus的所有架构决策。
当你的输入与输出比率为100:1且缓存token的成本是十分之一时,你想要稳定、可预测的提示前缀。你想要仅追加的上下文。你想要你的记忆系统与KV缓存命中率良好配合。这些不是风格偏好。它们是单位经济。
todo.md:一个文件中的记忆和注意力控制
Manus平均每个任务约50次工具调用。这是一长串操作,LLM因”中间丢失”效应而著名,长上下文中的信息被忽略。
Manus的解决方案很优雅:它们在复杂任务期间生成并反复更新todo.md清单。每次代理完成一个步骤,它重写todo文件,这个重写将当前计划放入上下文窗口的最近部分,正是模型最关注的地方。
这是一个微妙但重要的点。Markdown文件不仅存储信息。它还塑造注意力。基于数据库的RAG系统可以检索事实,但它不能解决”保持计划热”的问题,除非你也构建一个明确的计划工件,将其重新引入最近的上下文。Manus正是用文本文件做到这一点。
泄露的Manus系统提示(一个广泛流传的GitHub gist,拥有超过2,500个星标)从独立角度证实了这一点。提示包括明确的规则,要求代理创建todo.md作为清单,并在完成每个项目后立即更新。它们还指示代理保存中间结果,并将不同的参考信息保存在单独的文件中。
即使你对营销叙述持怀疑态度,操作提示也讲述了同样的故事:文件写入纪律被烘焙到harness中。
OpenClaw:添加检索而不放弃控制
如果Manus是”纯文件”案例,OpenClaw展示了下一步的样子。它将Markdown作为规范记忆表面,但在其上分层语义检索,而不需要外部托管向量数据库。
记忆布局
OpenClaw的记忆系统使用两种文件:
MEMORY.md 保存持久的、经过策划的信息(代理应该始终知道的内容)
memory/YYYY-MM-DD.md中的日期文件捕获日常笔记
这是”记忆作为文档”。人类可以打开这些文件,阅读它们,编辑它们,并使用Git进行版本控制。尝试用向量数据库做到这一点。
压缩问题(以及为什么它比嵌入更重要)
OpenClaw提出了一个大多数”只需使用数据库”论点忽略的生产问题:当上下文窗口填满时会发生什么?
OpenClaw实现了自动记忆刷新。当会话接近其上下文限制时,系统触发一个静默的代理轮次,告诉模型在压缩截断对话历史之前将持久记忆写入记忆文件。
这是实践证据,表明核心问题不是”我在哪里存储嵌入?”而是”我如何在压缩边界上保留状态?”文件直接解决了这个问题。代理写下它需要记住的内容,下一个会话将其读回。
语义层(构建在文件之上,而非替代文件)
对于”但向量搜索呢?”的人群,这里是OpenClaw变得有趣的地方。
OpenClaw可以在其Markdown记忆文件上构建小型向量索引。但关键词是”在之上”。文件是真相的来源。向量索引是在关键词搜索不足时查找笔记的派生能力。
它同时适用于远程嵌入和本地嵌入,并使用sqlite-vec在SQLite内运行向量搜索。没有托管基础设施。没有外部数据库。只是带有可选检索层的本地文件。
OpenClaw甚至包括带有明确调优旋钮的混合检索:默认vectorWeight为0.7,textWeight为0.3,加上MMR风格的多样化以减少冗余结果和时间衰减(具有可配置的半衰期),这样过时的笔记不会超过新鲜笔记。
这是一个成熟的、面向生产的设计。它承认纯关键词搜索在释义和同义词上会失效。但它通过索引现有文件来解决这个问题,而不是用数据库替换它们。
Claude Code:当供应商发布模式时
Claude Code很重要,因为它将Markdown记忆模式从社区约定转变为文档化的产品功能。
CLAUDE.md:无需数据库的分层指令
Claude Code的记忆系统以CLAUDE.md文件为中心,这些文件包含持久指令、规则、工作流和项目架构说明。模型在每次会话开始时读取这些文件。
聪明的部分是层次结构:
托管策略指令(OS特定的系统位置)用于组织范围的规则
项目指令(
./CLAUDE.md)通过源代码控制共享用户指令(
~/.claude/CLAUDE.md)用于个人偏好目录级文件,当Claude读取子目录中的文件时按需加载
这是渐进式披露。不是在启动时将所有内容倾入上下文,而是系统基于范围加载相关内容。这种”检索”不需要向量数据库。文件系统的目录结构就是检索机制。
一个重要的更正
Anthropic的博客文章将CLAUDE.md描述为成为”系统提示的一部分”。但实际文档更精确:CLAUDE.md内容作为系统提示之后的用户消息传递,而不是在其中。它是上下文,不是强制配置。
这很重要,因为它改变了”记忆”在操作上的含义。文件不是神奇的强制执行边界。它是一个标准化的上下文通道,需要保持简洁和一致才能很好地工作。Anthropic甚至建议将每个CLAUDE.md保持在约200行以下,并定期删除矛盾之处。
自动记忆:一个有上限的、基于文件的第二大脑
Claude Code还在~/.claude/projects/<project>/memory/为每个项目维护一个自动记忆目录,其中包含MEMORY.md文件和可选的主题文件。会话开始时仅加载MEMORY.md的前200行。主题文件按需加载。
这是对”记忆文件无界增长”批评的供应商设计的答案。Claude Code不是假装无限记忆是免费的,而是对始终加载的索引施加硬限制,并鼓励溢出到主题文件中。这是一个简单、实用的约束,回避了大多数”只需使用Markdown”论点忽略的扩展问题。
Markdown文件实际失败的地方
如果我假装文件解决一切,那我就是在害你。它们不。这个论点的诚实版本更窄但更有用:对于单用户或单线程代理工作流(尤其是本地编码代理),基于文件的记忆提供不成比例的价值,因为它与LLM的工作方式和运行成本相一致。
但确实存在真正的失败模式。
上下文预算压力。Claude Code明确警告CLAUDE.md每个会话消耗token,过大的文件会降低遵守度。文件在膨胀和内部矛盾之前工作。
并发。当多个代理或用户需要触摸相同的记忆时,并发文件写入可能会损坏数据。此时你需要数据库保证(原子性、隔离性、协调)。这甚至不是关于Markdown vs 数据库。这是关于文件系统 vs 数据库,在并发访问下数据库获胜。
大规模语义检索。Grep和关键词搜索在释义和同义词上会失效。随着你的知识库增长,向量搜索变得必要,而不是可选。OpenClaw的混合模式是对此的务实承认。
缓存失效成本。Manus发现一些”聪明”的动态行为,如在迭代中期添加和删除工具,实际上通过使KV缓存失效和混淆模型来降低性能。不是所有的复杂性都为你购买能力。有些只是为你购买更高的账单。
平衡架构
这三个系统的证据指向一个可能的平衡,比”文件 vs 数据库”更有用:
文件(通常是Markdown)作为主要接口。计划、约定、学习和指令存在于人类可读、版本可控的文本文件中。这是模型和人类都直接交互的层。
积极卸载到磁盘。大型工具输出被保存为带有可恢复引用(路径、URL)的文件,因此上下文可以缩小而不丢失信息。Manus称之为”上下文窗口=RAM,文件系统=磁盘”模型。
派生检索层。当规模需要语义搜索时,你在文件上构建索引。OpenClaw使用SQLite和sqlite-vec做到这一点。文件仍然是真相的来源。索引是搜索优化。
明确的升级路径。当记忆需要在并发访问下共享和正确时,你将基础转移到数据库。但即使这样,面向代理的接口仍然可以看起来像”文件夹中的文件”。
这不是一个激进的立场。它只是说:从最有效的最简单的事情开始,当操作需求迫使你时再添加基础设施。对于现在的一大类代理工作流,最有效的最简单的事情是Markdown文件。
这对向量数据库市场意味着什么
对VC资助的记忆基础设施的尴尬问题是真实的。但资金情况不会在这个论点下崩溃。它会分叉。
像Mem0(筹集2400万美元)、Letta(1000万美元种子轮,估值7000万美元)和Zep(其Graphiti项目超过20,000个GitHub星标)这样的记忆层初创公司专门解决文件优先系统难以解决的部分:跨部署的持久性、用户级个性化、大规模检索、治理和企业控制。
同时,向量搜索正在成为一种商品功能。调查数据显示采用率稳步攀升,向量功能出现在Postgres扩展、集成数据库功能和托管服务中。市场不是在文件和向量之间选择。它正在向两者的可组合组合移动。
底线(没有蝴蝶结)
“击败5000万美元向量数据库的Markdown文件”作为关于默认启动架构的论点最有效,而不是预测数据库没有角色。
更精确、有证据支持的论点是:这些成功的代理堆栈将文件视为状态的一等接口,然后仅在操作需求迫使它们时才添加检索和更强的基础。
如果你今天正在构建代理,你的第一直觉是设置向量数据库,退后一步。看看Manus、OpenClaw和Claude Code实际发布的内容。从Markdown文件开始。你以后总是可以添加数据库。
你可能不能反过来这么说。